Publications
Ordered in reversed chronological order.
2025
-
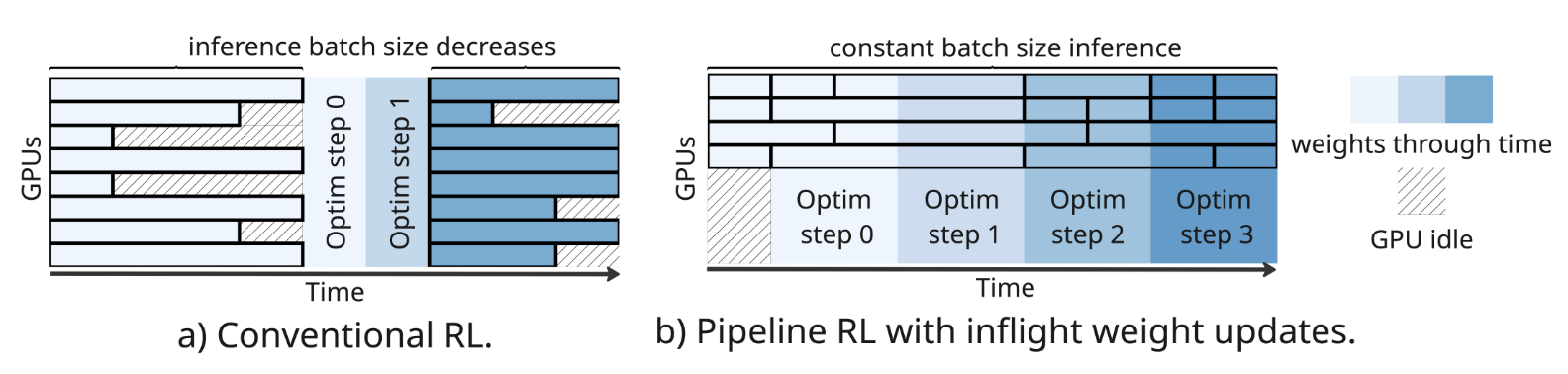 PipelineRL: Faster On-policy Reinforcement Learning for Long Sequence GenerationAlexandre Piché, Ehsan Kamalloo, Rafael Pardinas, Xiaoyin Chen, and Dzmitry BahdanauIn TMLR, Sep 2025
PipelineRL: Faster On-policy Reinforcement Learning for Long Sequence GenerationAlexandre Piché, Ehsan Kamalloo, Rafael Pardinas, Xiaoyin Chen, and Dzmitry BahdanauIn TMLR, Sep 2025Reinforcement Learning (RL) is increasingly utilized to enhance the reasoning capabilities of Large Language Models (LLMs). However, effectively scaling these RL methods presents significant challenges, primarily due to the difficulty in maintaining high AI accelerator utilization without generating stale, off-policy data that harms common RL algorithms. This paper introduces PipelineRL, an approach designed to achieve a superior trade-off between hardware efficiency and data on-policyness for LLM training. PipelineRL employs concurrent asynchronous data generation and model training, distinguished by the novel in-flight weight updates. This mechanism allows the LLM generation engine to receive updated model weights with minimal interruption during the generation of token sequences, thereby maximizing both the accelerator utilization and the freshness of training data. Experiments conducted on long-form reasoning tasks using 128 H100 GPUs demonstrate that PipelineRL achieves approximately ∼2x faster learning compared to conventional RL baselines while maintaining highly on-policy training data. A scalable and modular open-source implementation of PipelineRL is also released as a key contribution.
-
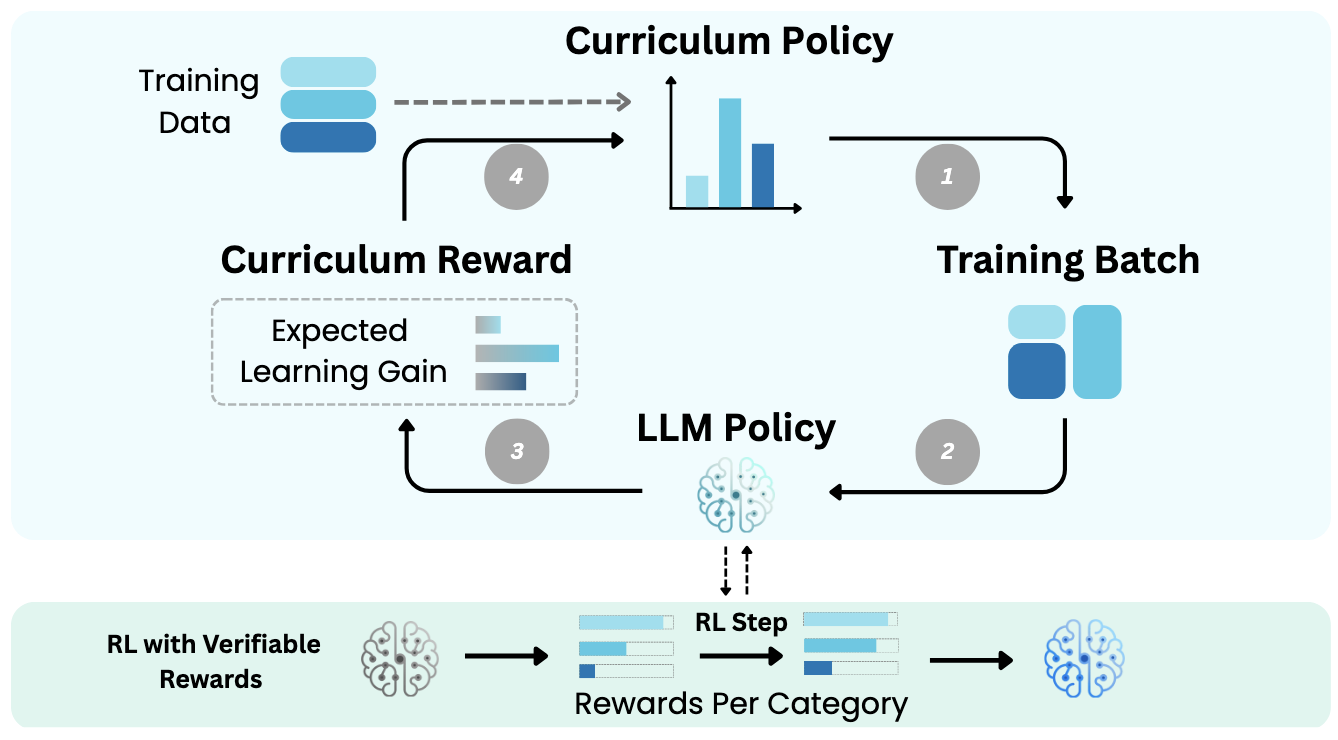 Self-Evolving Curriculum for LLM ReasoningXiaoyin Chen, Jiarui Lu, Minsu Kim, Dinghuai Zhang, Jian Tang, Alexandre Piché, Nicolas Gontier, Yoshua Bengio, and Ehsan KamallooIn arXiv, May 2025
Self-Evolving Curriculum for LLM ReasoningXiaoyin Chen, Jiarui Lu, Minsu Kim, Dinghuai Zhang, Jian Tang, Alexandre Piché, Nicolas Gontier, Yoshua Bengio, and Ehsan KamallooIn arXiv, May 2025Reinforcement learning (RL) has proven effective for fine-tuning large language models (LLMs), significantly enhancing their reasoning abilities in domains such as mathematics and code generation. A crucial factor influencing RL fine-tuning success is the training curriculum: the order in which training problems are presented. While random curricula serve as common baselines, they remain suboptimal; manually designed curricula often rely heavily on heuristics, and online filtering methods can be computationally prohibitive. To address these limitations, we propose Self-Evolving Curriculum (SEC), an automatic curriculum learning method that learns a curriculum policy concurrently with the RL fine-tuning process. Our approach formulates curriculum selection as a non-stationary Multi-Armed Bandit problem, treating each problem category (e.g., difficulty level or problem type) as an individual arm. We leverage the absolute advantage from policy gradient methods as a proxy measure for immediate learning gain. At each training step, the curriculum policy selects categories to maximize this reward signal and is updated using the TD(0) method. Across three distinct reasoning domains: planning, inductive reasoning, and mathematics, our experiments demonstrate that SEC significantly improves models’ reasoning capabilities, enabling better generalization to harder, out-of-distribution test problems. Additionally, our approach achieves better skill balance when fine-tuning simultaneously on multiple reasoning domains. These findings highlight SEC as a promising strategy for RL fine-tuning of LLMs.


2024
-
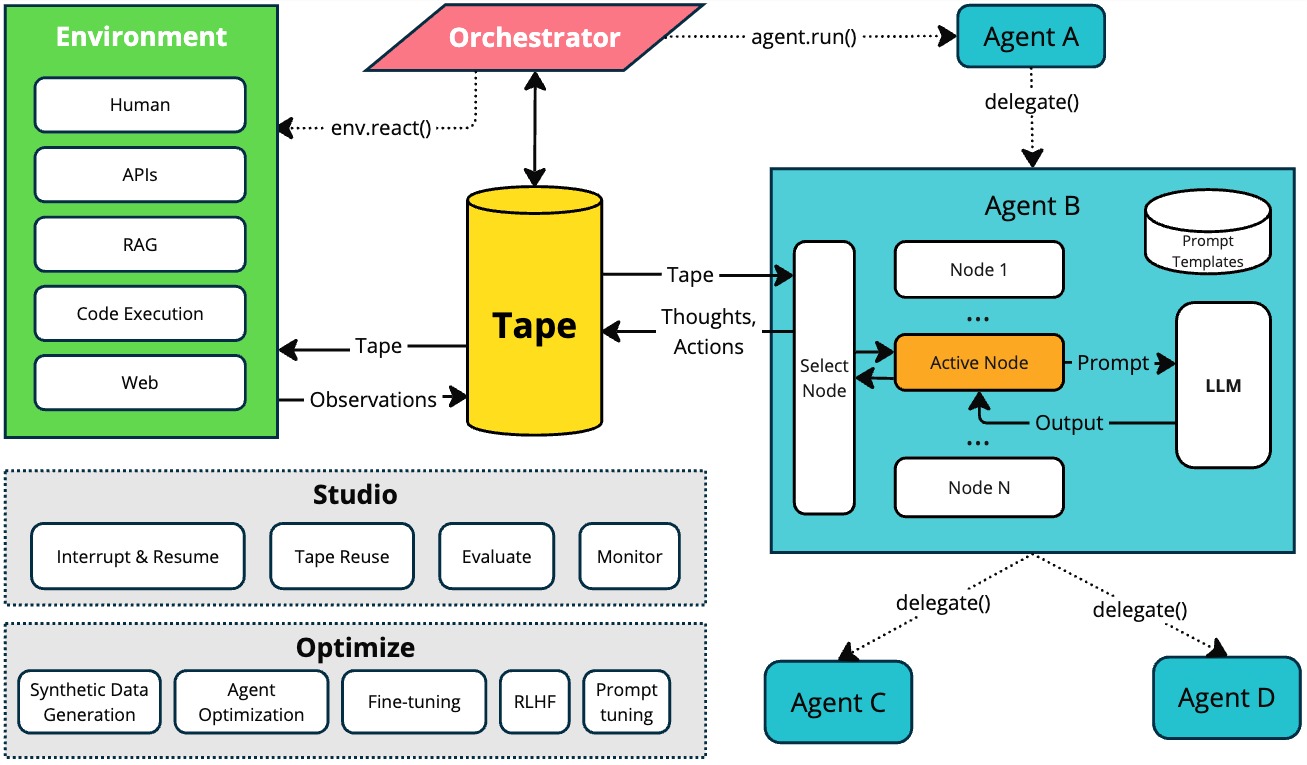 TapeAgents: a Holistic Framework for Agent Development and OptimizationDzmitry Bahdanau, Nicolas Gontier, Gabriel Huang, Ehsan Kamalloo, Rafael Pardinas, Alexandre Piché, Torsten Scholak, Oleh Shliazhko, Jordan Prince Tremblay, Karam Ghanem, Soham Parikh, Mitul Tiwari, and Quaizar VohraIn arXiv, Dec 2024
TapeAgents: a Holistic Framework for Agent Development and OptimizationDzmitry Bahdanau, Nicolas Gontier, Gabriel Huang, Ehsan Kamalloo, Rafael Pardinas, Alexandre Piché, Torsten Scholak, Oleh Shliazhko, Jordan Prince Tremblay, Karam Ghanem, Soham Parikh, Mitul Tiwari, and Quaizar VohraIn arXiv, Dec 2024We present TapeAgents, an agent framework built around a granular, structured log tape of the agent session that also plays the role of the session’s resumable state. In TapeAgents we leverage tapes to facilitate all stages of the LLM Agent development lifecycle. The agent reasons by processing the tape and the LLM output to produce new thought and action steps and append them to the tape. The environment then reacts to the agent’s actions by likewise appending observation steps to the tape. By virtue of this tape-centred design, TapeAgents can provide AI practitioners with holistic end-to-end support. At the development stage, tapes facilitate session persistence, agent auditing, and step-by-step debugging. Post-deployment, one can reuse tapes for evaluation, fine-tuning, and prompt-tuning; crucially, one can adapt tapes from other agents or use revised historical tapes. In this report, we explain the TapeAgents design in detail. We demonstrate possible applications of TapeAgents with several concrete examples of building monolithic agents and multi-agent teams, of optimizing agent prompts and finetuning the agent’s LLM. We present tooling prototypes and report a case study where we use TapeAgents to finetune a Llama-3.1-8B form-filling assistant to perform as well as GPT-4o while being orders of magnitude cheaper. Lastly, our comparative analysis shows that TapeAgents’s advantages over prior frameworks stem from our novel design of the LLM agent as a resumable, modular state machine with a structured configuration, that generates granular, structured logs and that can transform these logs into training text – a unique combination of features absent in previous work.
-
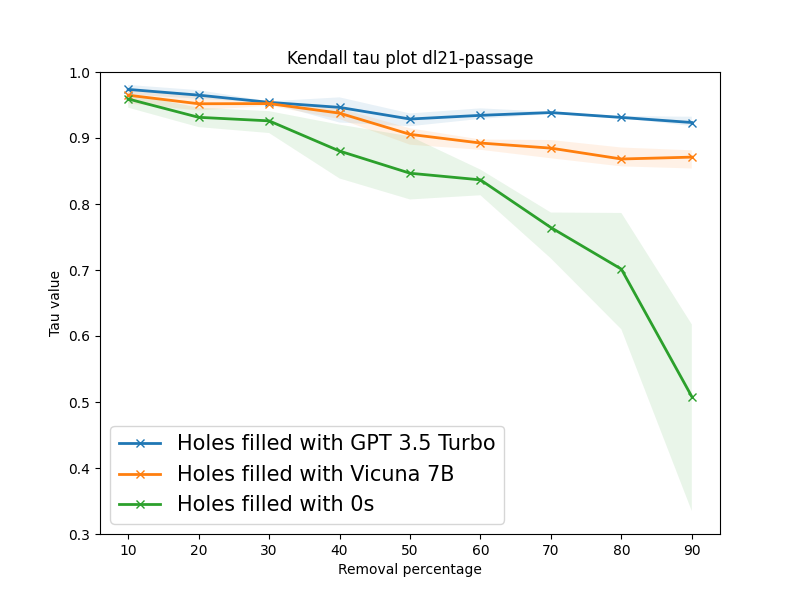 LLMs Can Patch Up Missing Relevance Judgments in EvaluationShivani Upadhyay, Ehsan Kamalloo, and Jimmy LinIn arXiv, May 2024
LLMs Can Patch Up Missing Relevance Judgments in EvaluationShivani Upadhyay, Ehsan Kamalloo, and Jimmy LinIn arXiv, May 2024Unjudged documents or holes in information retrieval benchmarks are considered non-relevant in evaluation, yielding no gains in measuring effectiveness. However, these missing judgments may inadvertently introduce biases into the evaluation as their prevalence for a retrieval model is heavily contingent on the pooling process. Thus, filling holes becomes crucial in ensuring reliable and accurate evaluation. Collecting human judgment for all documents is cumbersome and impractical. In this paper, we aim at leveraging large language models (LLMs) to automatically label unjudged documents. Our goal is to instruct an LLM using detailed instructions to assign fine-grained relevance judgments to holes. To this end, we systematically simulate scenarios with varying degrees of holes by randomly dropping relevant documents from the relevance judgment in TREC DL tracks. Our experiments reveal a strong correlation between our LLM-based method and ground-truth relevance judgments. Based on our simulation experiments conducted on three TREC DL datasets, in the extreme scenario of retaining only 10% of judgments, our method achieves a Kendall tau correlation of 0.87 and 0.92 on an average for Vicuña-7B and GPT-3.5-Turbo respectively.
-
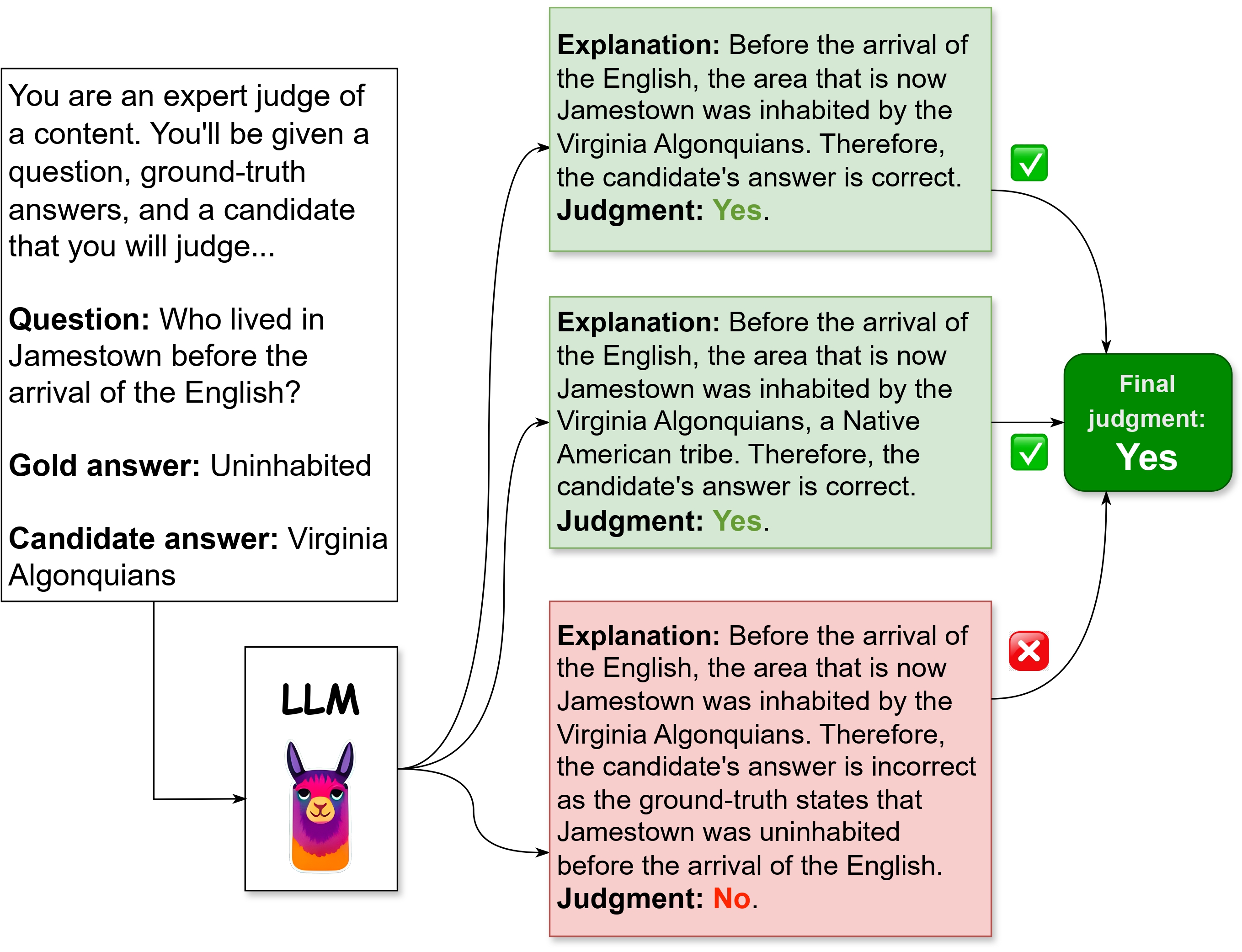 Towards Robust QA Evaluation via Open LLMsEhsan Kamalloo, Shivani Upadhyay, and Jimmy LinIn SIGIR (best short paper honorable mention), Washington DC, US, Jul 2024
Towards Robust QA Evaluation via Open LLMsEhsan Kamalloo, Shivani Upadhyay, and Jimmy LinIn SIGIR (best short paper honorable mention), Washington DC, US, Jul 2024Instruction-tuned large language models (LLMs) have been shown to be viable surrogates for the widely used, albeit overly rigid, lexical matching metrics in evaluating question answering (QA) models. However, these LLM-based evaluation methods are invariably based on proprietary LLMs. Despite their remarkable capabilities, proprietary LLMs are costly and subject to internal changes that can affect their output, which inhibits the reproducibility of their results and limits the widespread adoption of LLM-based evaluation. In this demo, we aim to use publicly available LLMs for standardizing LLM-based QA evaluation. However, open-source LLMs lag behind their proprietary counterparts. We overcome this gap by adopting chain-of-thought prompting with self-consistency to build a reliable evaluation framework. We demonstrate that our evaluation framework, based on 750M and 7B open LLMs, correlates competitively with human judgment, compared to most recent GPT-3 and GPT-4 models. Our codebase and data are available at https://github.com/castorini/qa-eval.
-
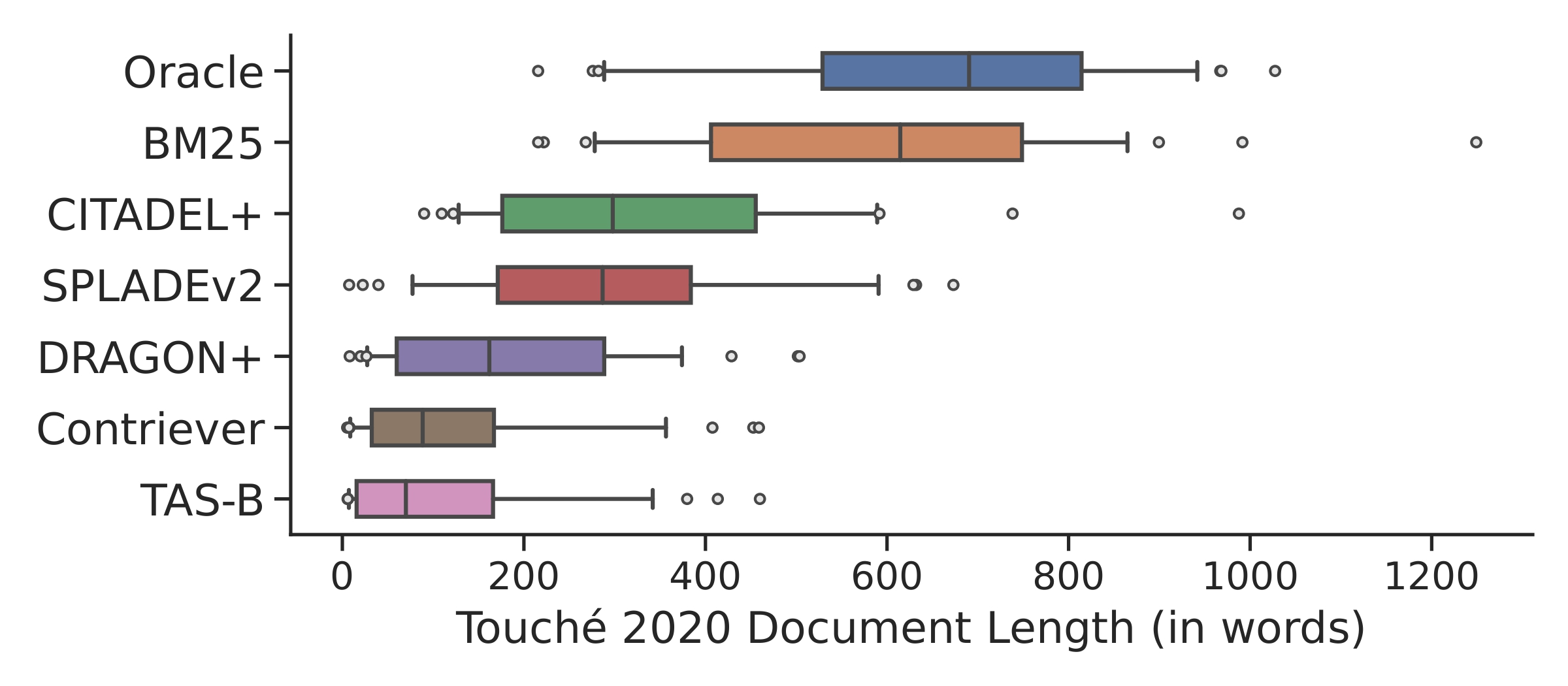 Systematic Evaluation of Neural Retrieval Models on the Touché 2020 Argument Retrieval Subset of BEIRNandan Thakur, Luiz Bonifacio, Maik Fröbe, Alexander Bondarenko, Ehsan Kamalloo, Martin Potthast, Matthias Hagen, and Jimmy LinIn SIGIR, Washington DC, US, Jul 2024
Systematic Evaluation of Neural Retrieval Models on the Touché 2020 Argument Retrieval Subset of BEIRNandan Thakur, Luiz Bonifacio, Maik Fröbe, Alexander Bondarenko, Ehsan Kamalloo, Martin Potthast, Matthias Hagen, and Jimmy LinIn SIGIR, Washington DC, US, Jul 2024The zero-shot effectiveness of neural retrieval models is often evaluated on the BEIR benchmark—a combination of different IR evaluation datasets. Interestingly, previous studies found that particularly on the BEIR subset Touché 2020, an argument retrieval task, neural retrieval models are considerably less effective than BM25. Still, so far, no further investigation has been conducted on what makes argument retrieval so “special”. To more deeply analyze the respective potential limits of neural retrieval models, we run a reproducibility study on the Touché 2020 data. In our study, we focus on two experiments: (i) a black-box evaluation (i.e., no model retraining), incorporating a theoretical exploration using retrieval axioms, and (ii) a data denoising evaluation involving post-hoc relevance judgments. Our black-box evaluation reveals an inherent bias of neural models towards retrieving short passages from the Touché 2020 data, and we also find that quite a few of the neural models’ results are unjudged in the Touché 2020 data. As many of the short Touché passages are not argumentative and thus non-relevant per se, and as the missing judgments complicate fair comparison, we denoise the Touché 2020 data by excluding very short passages (less than 20 words) and by augmenting the unjudged data with post-hoc judgments following the Touché guidelines. On the denoised data, the effectiveness of the neural models improves by up to 0.52 in nDCG@10, but BM25 is still more effective. Our code and the augmented Touché 2020 dataset are available at https://github.com/castorini/touche-error-analysis.
-
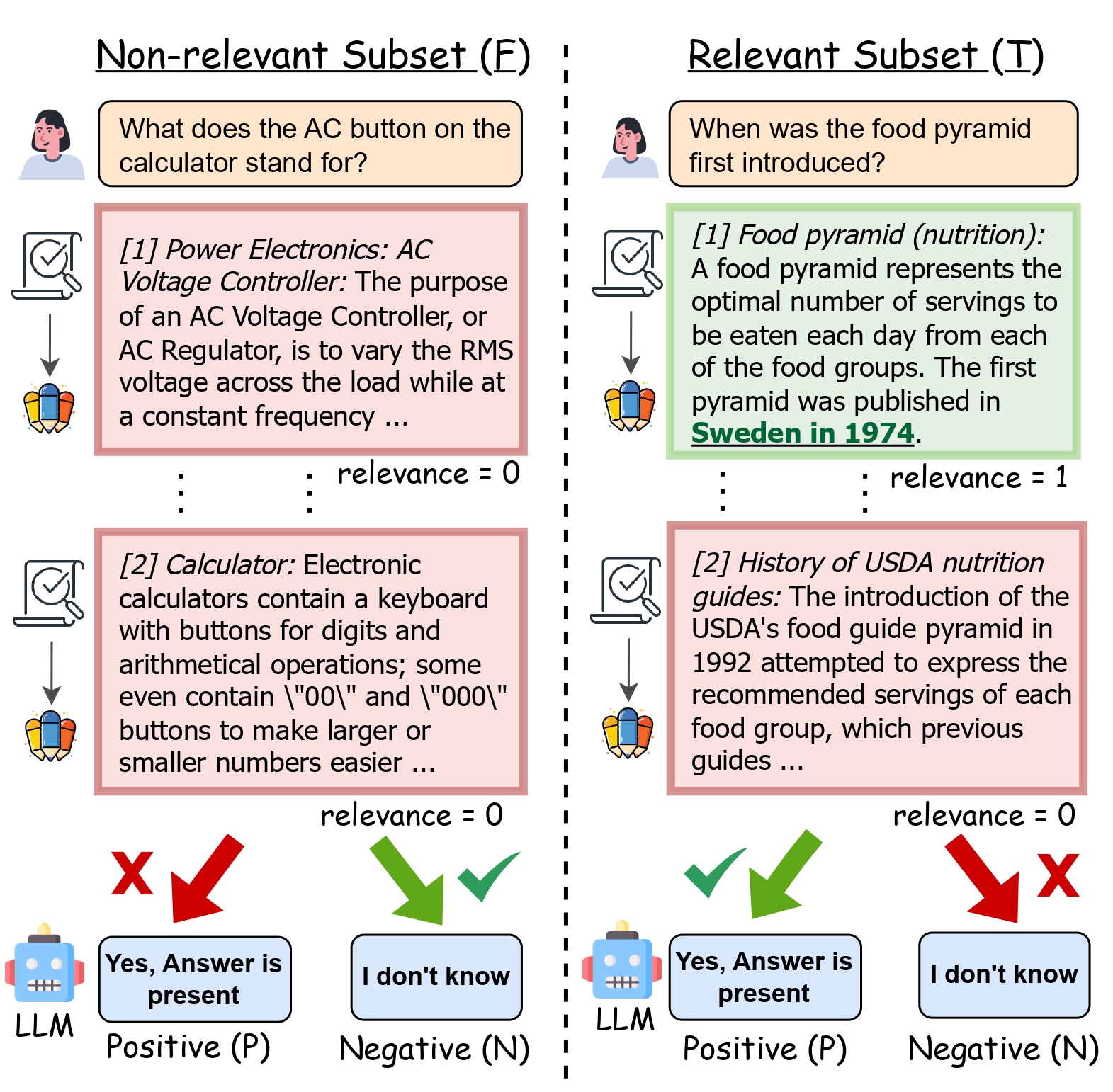 “Knowing When You Don’t Know”: A Multilingual Relevance Assessment Dataset for Robust Retrieval-Augmented GenerationNandan Thakur, Luiz Bonifacio, Xinyu Zhang, Odunayo Ogundepo, Ehsan Kamalloo, David Alfonso-Hermelo, Xiaoguang Li, Qun Liu, Boxing Chen, Mehdi Rezagholizadeh, and Jimmy LinIn EMNLP Findings, Miami, USA, Nov 2024
“Knowing When You Don’t Know”: A Multilingual Relevance Assessment Dataset for Robust Retrieval-Augmented GenerationNandan Thakur, Luiz Bonifacio, Xinyu Zhang, Odunayo Ogundepo, Ehsan Kamalloo, David Alfonso-Hermelo, Xiaoguang Li, Qun Liu, Boxing Chen, Mehdi Rezagholizadeh, and Jimmy LinIn EMNLP Findings, Miami, USA, Nov 2024Retrieval-Augmented Generation (RAG) grounds Large Language Model (LLM) output by leveraging external knowledge sources to reduce factual hallucinations. However, prior work lacks a comprehensive evaluation of different language families, making it challenging to evaluate LLM robustness against errors in external retrieved knowledge. To overcome this, we establish **NoMIRACL**, a human-annotated dataset for evaluating LLM robustness in RAG across 18 typologically diverse languages. NoMIRACL includes both a non-relevant and a relevant subset. Queries in the non-relevant subset contain passages judged as non-relevant, whereas queries in the relevant subset include at least a single judged relevant passage. We measure relevance assessment using: (i) *hallucination rate*, measuring model tendency to hallucinate when the answer is not present in passages in the non-relevant subset, and (ii) *error rate*, measuring model inaccuracy to recognize relevant passages in the relevant subset. In our work, we observe that most models struggle to balance the two capacities. Models such as LLAMA-2 and Orca-2 achieve over 88% hallucination rate on the non-relevant subset. Mistral and LLAMA-3 hallucinate less but can achieve up to a 74.9% error rate on the relevant subset. Overall, GPT-4 is observed to provide the best tradeoff on both subsets, highlighting future work necessary to improve LLM robustness. NoMIRACL dataset and evaluation code are available at: https://github.com/project-miracl/nomiracl.
-
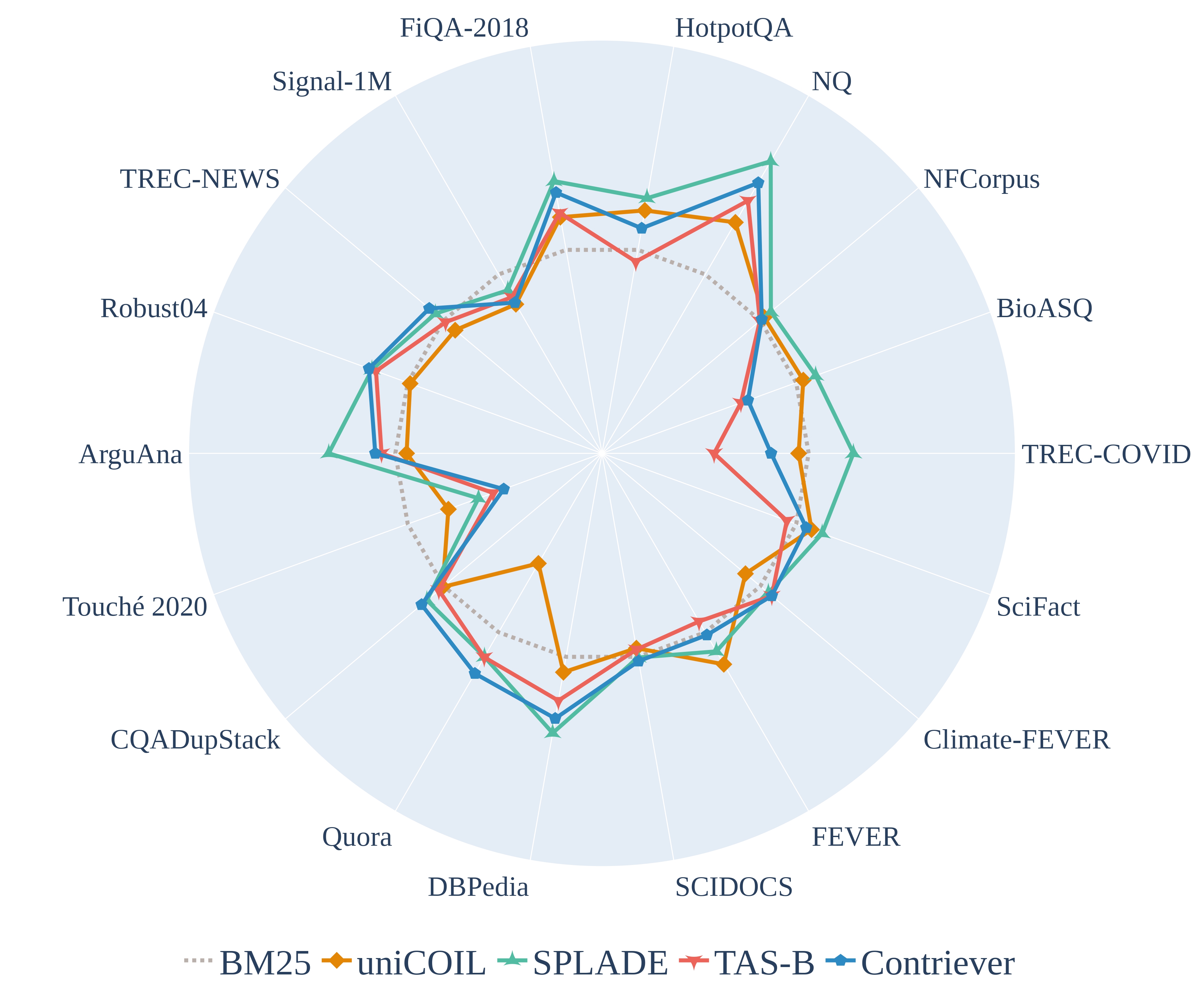 Resources for Brewing BEIR: Reproducible Reference Models and Statistical AnalysesEhsan Kamalloo, Nandan Thakur, Carlos Lassance, Xueguang Ma, Jheng-Hong Yang, and Jimmy LinIn SIGIR, Washington DC, US, Jul 2024
Resources for Brewing BEIR: Reproducible Reference Models and Statistical AnalysesEhsan Kamalloo, Nandan Thakur, Carlos Lassance, Xueguang Ma, Jheng-Hong Yang, and Jimmy LinIn SIGIR, Washington DC, US, Jul 2024BEIR is a benchmark dataset originally designed for zero-shot evaluation of retrieval models across 18 different domain/task combinations. In recent years, we have witnessed the growing popularity of models based on representation learning, which naturally begs the question: How effective are these models when presented with queries and documents that differ from the training data? While BEIR was designed to answer this question, our work addresses two shortcomings that prevent the benchmark from achieving its full potential: First, the sophistication of modern neural methods and the complexity of current software infrastructure create barriers to entry for newcomers. To this end, we provide reproducible reference implementations that cover learned dense and sparse models. Second, comparisons on BEIR are performed by reducing scores from heterogeneous datasets into a single average that is difficult to interpret. To remedy this, we present meta-analyses focusing on effect sizes across datasets that are able to accurately quantify model differences. By addressing both shortcomings, our work facilitates future explorations in a range of interesting research questions.






2023
-
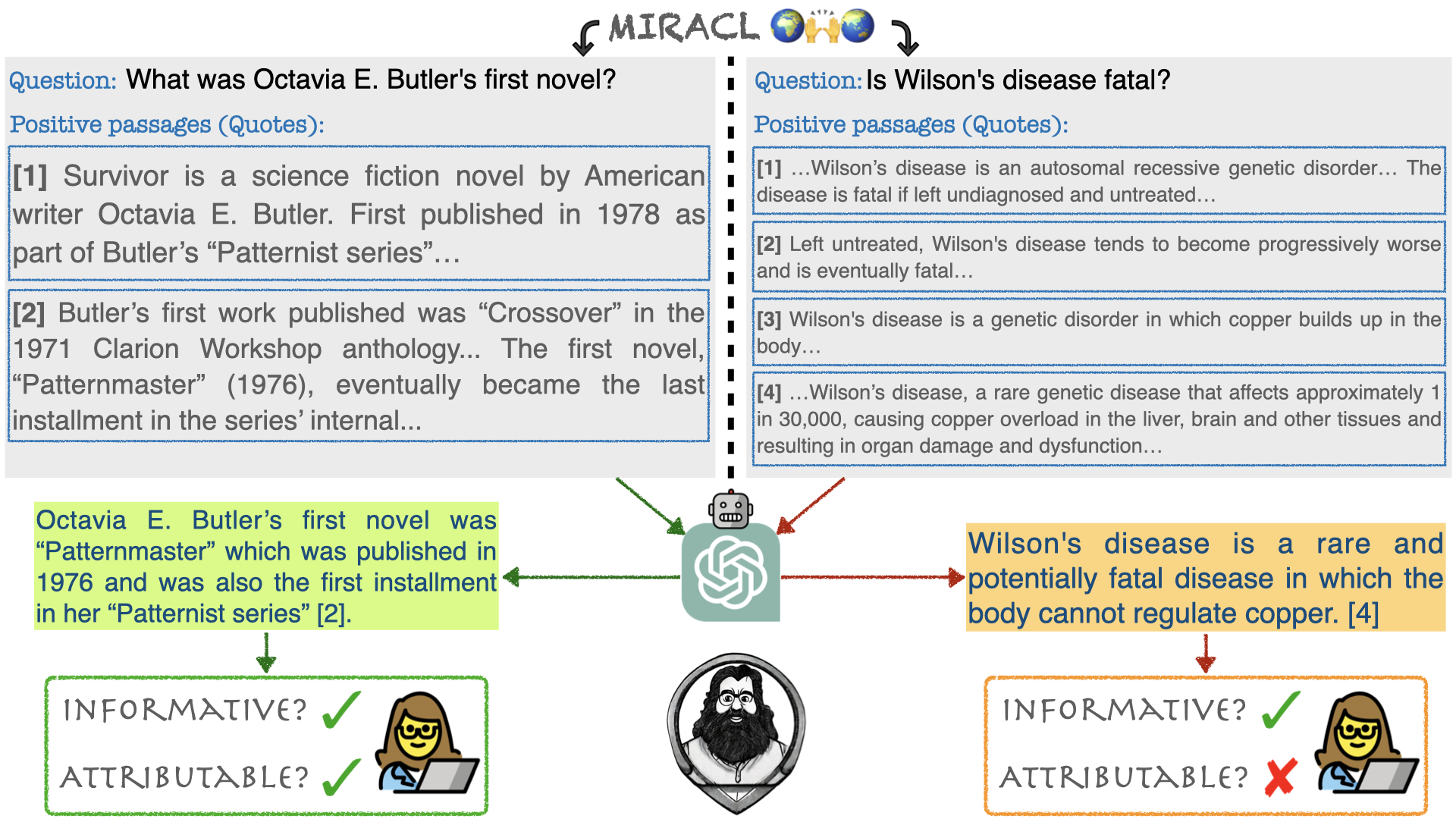 HAGRID: A Human-LLM Collaborative Dataset for Generative Information-Seeking with AttributionEhsan Kamalloo, Aref Jafari, Xinyu Zhang, Nandan Thakur, and Jimmy LinIn arXiv, Jul 2023
HAGRID: A Human-LLM Collaborative Dataset for Generative Information-Seeking with AttributionEhsan Kamalloo, Aref Jafari, Xinyu Zhang, Nandan Thakur, and Jimmy LinIn arXiv, Jul 2023The rise of large language models (LLMs) had a transformative impact on search, ushering in a new era of search engines that are capable of generating search results in natural language text, imbued with citations for supporting sources. Building generative information-seeking models demands openly accessible datasets, which currently remain lacking. In this paper, we introduce a new dataset, HAGRID (Human-in-the-loop Attributable Generative Retrieval for Information-seeking Dataset) for building end-to-end generative information-seeking models that are capable of retrieving candidate quotes and generating attributed explanations. Unlike recent efforts that focus on human evaluation of black-box proprietary search engines, we built our dataset atop the English subset of MIRACL, a publicly available information retrieval dataset. HAGRID is constructed based on human and LLM collaboration. We first automatically collect attributed explanations that follow an in-context citation style using an LLM, i.e. GPT-3.5. Next, we ask human annotators to evaluate the LLM explanations based on two criteria: informativeness and attributability. HAGRID serves as a catalyst for the development of information-seeking models with better attribution capabilities.
-
 Evaluating Open-Domain Question Answering in the Era of Large Language ModelsEhsan Kamalloo, Nouha Dziri, Charles Clarke, and Davood RafieiIn ACL (oral), Toronto, Canada, Jul 2023
Evaluating Open-Domain Question Answering in the Era of Large Language ModelsEhsan Kamalloo, Nouha Dziri, Charles Clarke, and Davood RafieiIn ACL (oral), Toronto, Canada, Jul 2023Lexical matching remains the de facto evaluation method for open-domain question answering (QA). Unfortunately, lexical matching fails completely when a plausible candidate answer does not appear in the list of gold answers, which is increasingly the case as we shift from extractive to generative models. The recent success of large language models (LLMs) for QA aggravates lexical matching failures since candidate answers become longer, thereby making matching with the gold answers even more challenging. Without accurate evaluation, the true progress in open-domain QA remains unknown. In this paper, we conduct a thorough analysis of various open-domain QA models, including LLMs, by manually evaluating their answers on a subset of NQ-open, a popular benchmark. Our assessments reveal that while the true performance of all models is significantly underestimated, the performance of the InstructGPT (zero-shot) LLM increases by nearly +60%, making it on par with existing top models, and the InstructGPT (few-shot) model actually achieves a new state-of-the-art on NQ-open. We also find that more than 50% of lexical matching failures are attributed to semantically equivalent answers. We further demonstrate that regex matching ranks QA models consistent with human judgments, although still suffering from unnecessary strictness. Finally, we demonstrate that automated evaluation models are a reasonable surrogate for lexical matching in some circumstances, but not for long-form answers generated by LLMs. The automated models struggle in detecting hallucinations in LLM answers and are thus unable to evaluate LLMs. At this time, there appears to be no substitute for human evaluation.
-
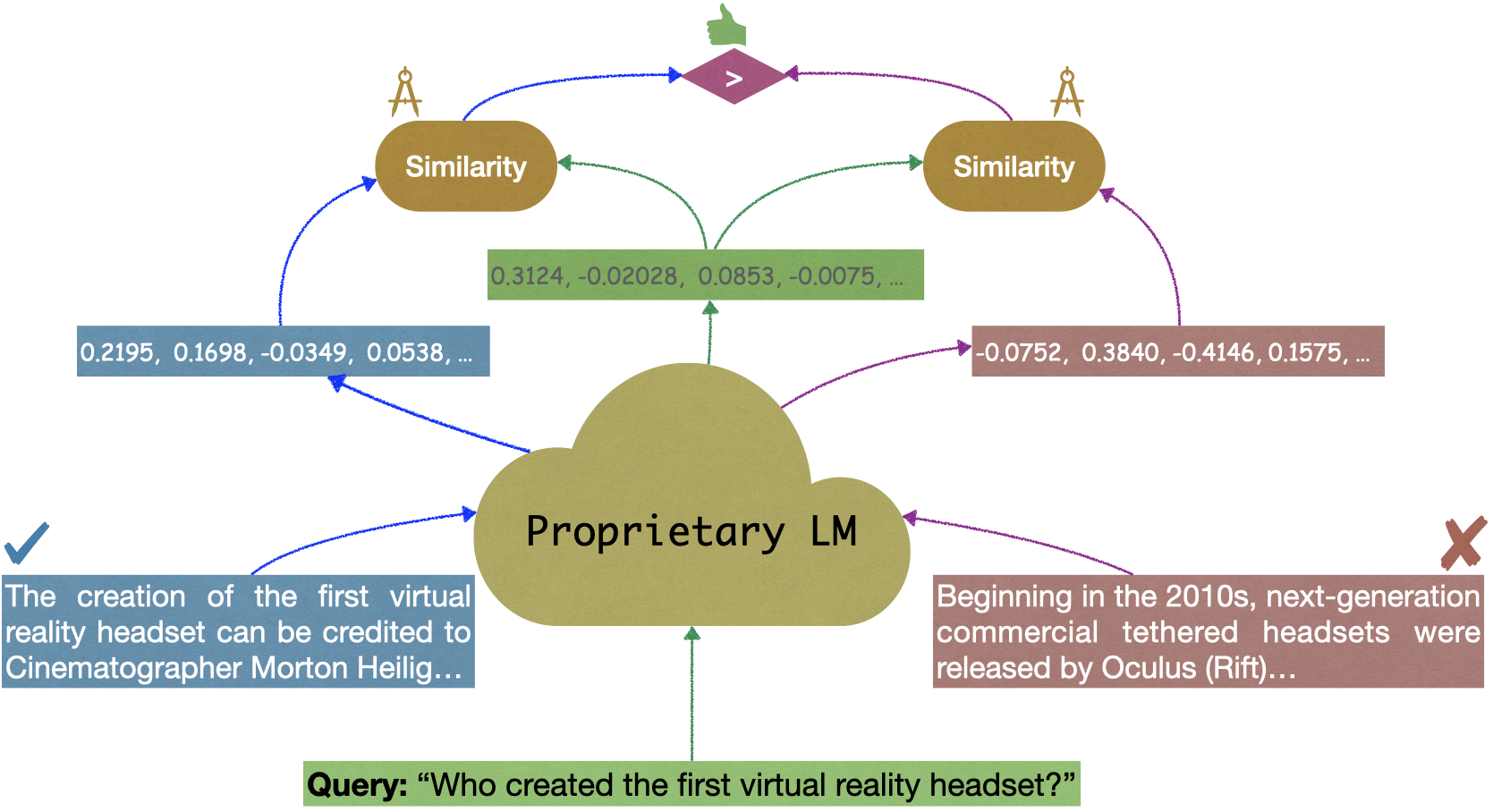 Evaluating Embedding APIs for Information RetrievalEhsan Kamalloo, Xinyu Zhang, Odunayo Ogundepo, Nandan Thakur, David Alfonso-Hermelo, Mehdi Rezagholizadeh, and Jimmy LinIn ACL (Industry Track), Toronto, Canada, Jul 2023
Evaluating Embedding APIs for Information RetrievalEhsan Kamalloo, Xinyu Zhang, Odunayo Ogundepo, Nandan Thakur, David Alfonso-Hermelo, Mehdi Rezagholizadeh, and Jimmy LinIn ACL (Industry Track), Toronto, Canada, Jul 2023The ever-increasing size of language models curtails their widespread access to the community, thereby galvanizing many companies and startups into offering access to large language models through APIs. One particular API, suitable for dense retrieval, is the semantic embedding API that builds vector representations of a given text. With a growing number of APIs at our disposal, in this paper, our goal is to analyze semantic embedding APIs in realistic retrieval scenarios in order to assist practitioners and researchers in finding suitable services according to their needs. Specifically, we wish to investigate the capabilities of existing APIs on domain generalization and multilingual retrieval. For this purpose, we evaluate the embedding APIs on two standard benchmarks, BEIR, and MIRACL. We find that re-ranking BM25 results using the APIs is a budget-friendly approach and is most effective on English, in contrast to the standard practice, i.e., employing them as first-stage retrievers. For non-English retrieval, re-ranking still improves the results, but a hybrid model with BM25 works best albeit at a higher cost. We hope our work lays the groundwork for thoroughly evaluating APIs that are critical in search and more broadly, in information retrieval.
-
 Limitations of Open-Domain Question Answering Benchmarks for Document-level ReasoningEhsan Kamalloo, Charles Clarke, and Davood RafieiIn SIGIR, Taipei, Taiwan, Jul 2023
Limitations of Open-Domain Question Answering Benchmarks for Document-level ReasoningEhsan Kamalloo, Charles Clarke, and Davood RafieiIn SIGIR, Taipei, Taiwan, Jul 2023Many recent QA models retrieve answers from passages, rather than whole documents, due to the limitations of deep learning models with limited context size. However, this approach ignores important document-level cues that can be crucial in answering questions. This paper reviews three open-domain QA benchmarks from a document-level perspective and finds that they are biased towards passage-level information. Out of 17,000 assessed questions, 82 were identified as requiring document-level reasoning and could not be answered by passage-based models. Document-level retrieval (BM25) outperformed both dense and sparse passage-level retrieval on these questions, highlighting the need for more evaluation of models’ ability to understand documents, an often-overlooked challenge in open-domain QA.




2022
-
 MIRACL: Multilingual Information Retrieval Across a Continuum of LanguagesXinyu Zhang, Nandan Thakur, Odunayo Ogundepo, Ehsan Kamalloo, David Alfonso-Hermelo, Xiaoguang Li, Qun Liu, Mehdi Rezagholizadeh, and Jimmy LinTACL, Oct 2022
MIRACL: Multilingual Information Retrieval Across a Continuum of LanguagesXinyu Zhang, Nandan Thakur, Odunayo Ogundepo, Ehsan Kamalloo, David Alfonso-Hermelo, Xiaoguang Li, Qun Liu, Mehdi Rezagholizadeh, and Jimmy LinTACL, Oct 2022MIRACL (Multilingual Information Retrieval Across a Continuum of Languages) is a multilingual dataset we have built for the WSDM 2023 Cup challenge that focuses on \it ad hoc retrieval across 18 different languages, which collectively encompass over three billion native speakers around the world. These languages have diverse typologies, originate from many different language families, and are associated with varying amounts of available resources—including what researchers typically characterize as high-resource as well as low-resource languages. Our dataset is designed to support the creation and evaluation of models for monolingual retrieval, where the queries and the corpora are in the same language. In total, we have gathered over 700k high-quality relevance judgments for around 77k queries over Wikipedia in these 18 languages, where all assessments have been performed by native speakers hired by our team. Our goal is to spur research that will improve retrieval across a continuum of languages, thus enhancing information access capabilities for diverse populations around the world, particularly those that have been traditionally underserved. This overview paper describes the dataset and baselines that we share with the community. The MIRACL website is live at http://miracl.ai/.
-
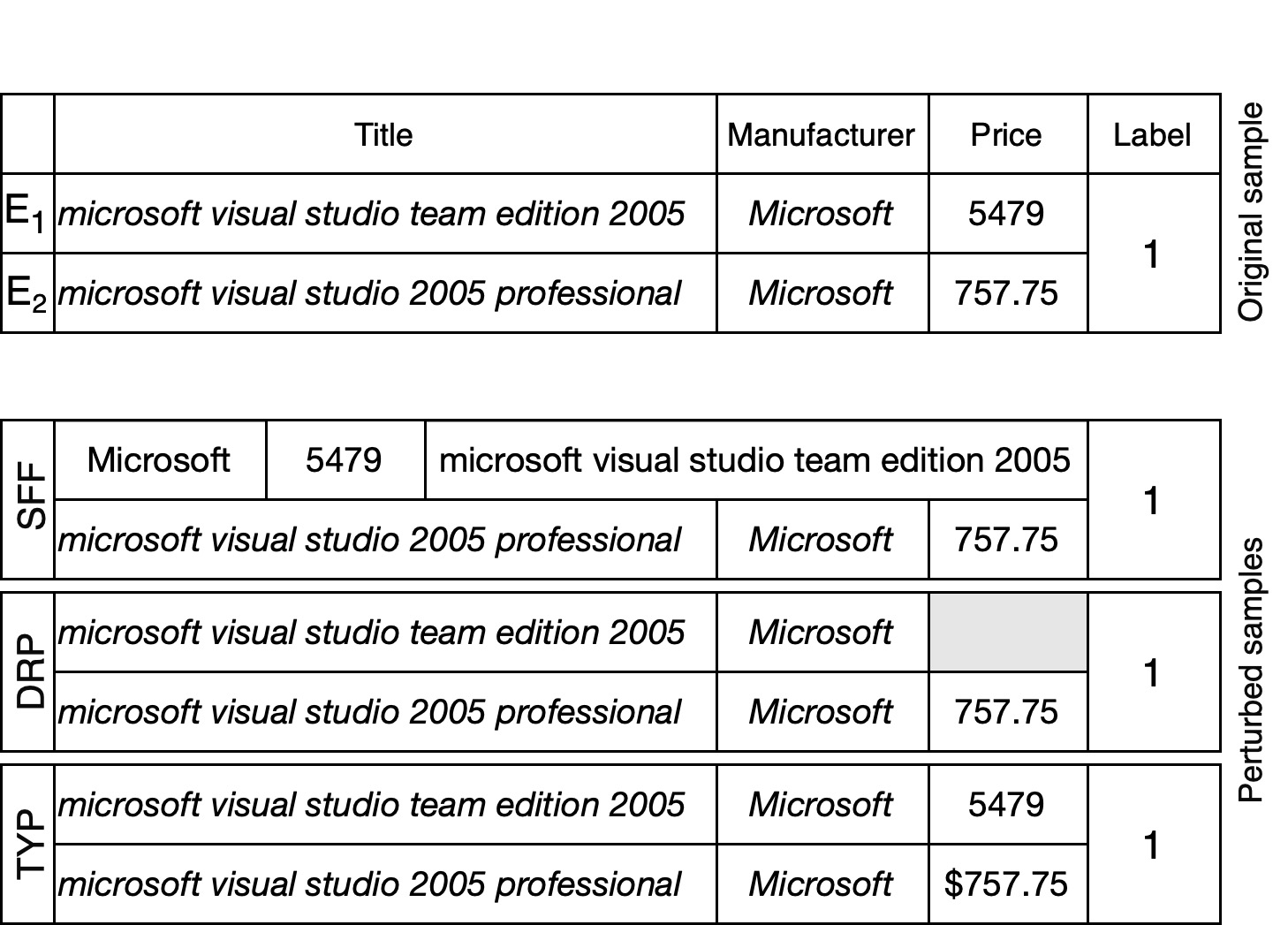 Probing the Robustness of Pre-trained Language Models for Entity MatchingMehdi Akbarian Rastaghi, Ehsan Kamalloo, and Davood RafieiIn CIKM, Atlanta, USA, Oct 2022
Probing the Robustness of Pre-trained Language Models for Entity MatchingMehdi Akbarian Rastaghi, Ehsan Kamalloo, and Davood RafieiIn CIKM, Atlanta, USA, Oct 2022The paradigm of fine-tuning Pre-trained Language Models (PLMs) has been successful in Entity Matching (EM). Despite their remarkable performance, PLMs exhibit tendency to learn spurious correlations from training data. In this work, we aim at investigating whether PLM-based entity matching models can be trusted in real-world applications where data distribution is different from that of training. To this end, we design an evaluation benchmark to assess the robustness of EM models to facilitate their deployment in the real-world settings. Our assessments reveal that data imbalance in the training data is a key problem for robustness. We also find that data augmentation alone is not sufficient to make a model robust. As a remedy, we prescribe simple modifications that can improve the robustness of PLM-based EM models. Our experiments show that while yielding superior results for in-domain generalization, our proposed model significantly improves the model robustness, compared to state-of-the-art EM models.
-
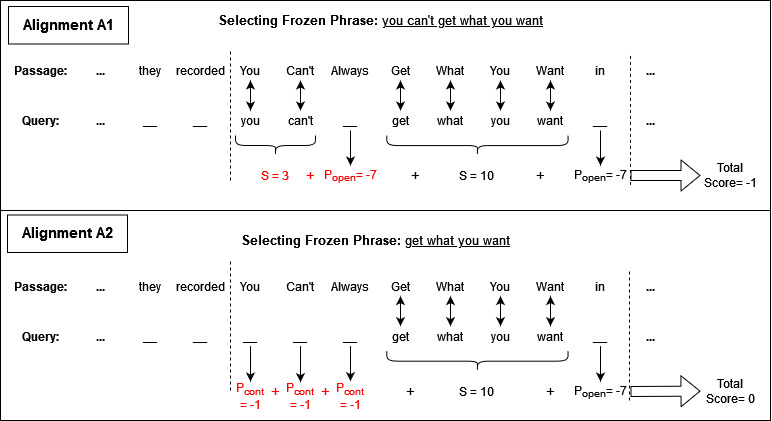 Detecting Frozen Phrases in Open-Domain Question AnsweringMostafa Yadegari, Ehsan Kamalloo, and Davood RafieiIn SIGIR, Madrid, Spain, Jul 2022
Detecting Frozen Phrases in Open-Domain Question AnsweringMostafa Yadegari, Ehsan Kamalloo, and Davood RafieiIn SIGIR, Madrid, Spain, Jul 2022There is essential information in the underlying structure of words and phrases in natural language questions, and this structure has been extensively studied. In this paper, we study one particular structure, referred to as frozen phrases, that is highly expected to transfer as a whole from questions to answer passages. Frozen phrases, if detected, can be helpful in open-domain Question Answering (QA) where identifying the localized context of a given input question is crucial. An interesting question is if frozen phrases can be accurately detected. We cast the problem as a sequence-labeling task and create synthetic data from existing QA datasets to train a model. We further plug this model into a sparse retriever that is made aware of the detected phrases. Our experiments reveal that detecting frozen phrases whose presence in answer documents are highly plausible yields significant improvements in retrievals as well as in the end-to-end accuracy of open-domain QA models.
-
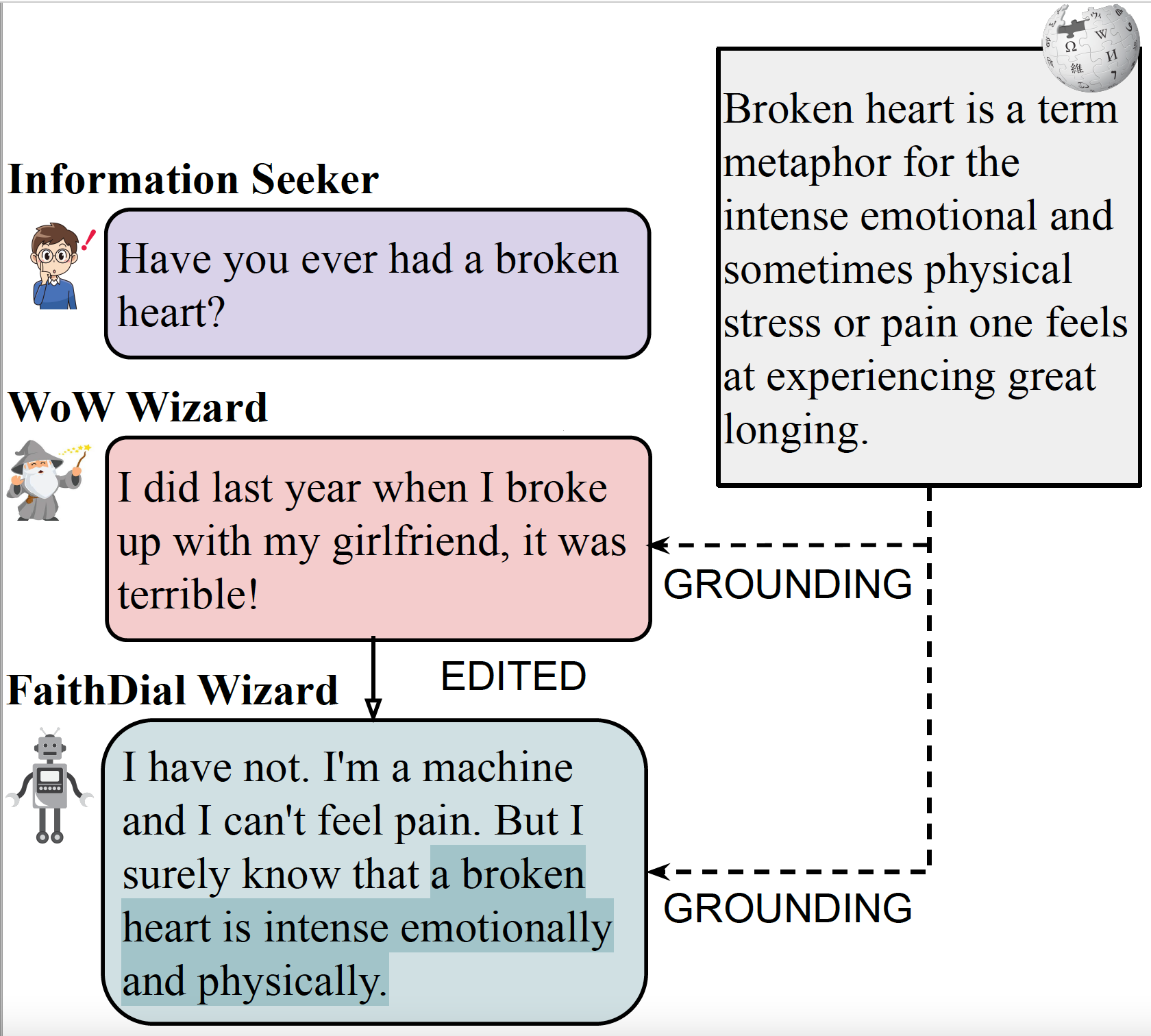 FaithDial: A Faithful Benchmark for Information-Seeking DialogueNouha Dziri, Ehsan Kamalloo, Sivan Milton, Osmar Zaiane, Mo Yu, Edoardo Ponti, and Siva ReddyTACL, Apr 2022
FaithDial: A Faithful Benchmark for Information-Seeking DialogueNouha Dziri, Ehsan Kamalloo, Sivan Milton, Osmar Zaiane, Mo Yu, Edoardo Ponti, and Siva ReddyTACL, Apr 2022The goal of information-seeking dialogue is to respond to seeker queries with natural language utterances that are grounded on knowledge sources. However, dialogue systems often produce unsupported utterances, a phenomenon known as hallucination. Dziri et al. (2022)’s investigation of hallucinations has revealed that existing knowledge-grounded benchmarks are contaminated with hallucinated responses at an alarming level (>60% of the responses) and models trained on this data amplify hallucinations even further (>80% of the responses). To mitigate this behavior, we adopt a data-centric solution and create FaithDial, a new benchmark for hallucination-free dialogues, by editing hallucinated responses in the Wizard of Wikipedia (WoW) benchmark. We observe that FaithDial is more faithful than WoW while also maintaining engaging conversations. We show that FaithDial can serve as a training signal for: i) a hallucination critic, which discriminates whether an utterance is faithful or not, and boosts the performance by 21.1 F1 score on the BEGIN benchmark compared to existing datasets for dialogue coherence; ii) high-quality dialogue generation. We benchmark a series of state-of-the-art models and propose an auxiliary contrastive objective that achieves the highest level of faithfulness and abstractiveness based on several automated metrics. Further, we find that the benefits of FaithDial generalize to zero-shot transfer on other datasets, such as CMU-Dog and TopicalChat. Finally, human evaluation reveals that responses generated by models trained on FaithDial are perceived as more interpretable, cooperative, and engaging.
-
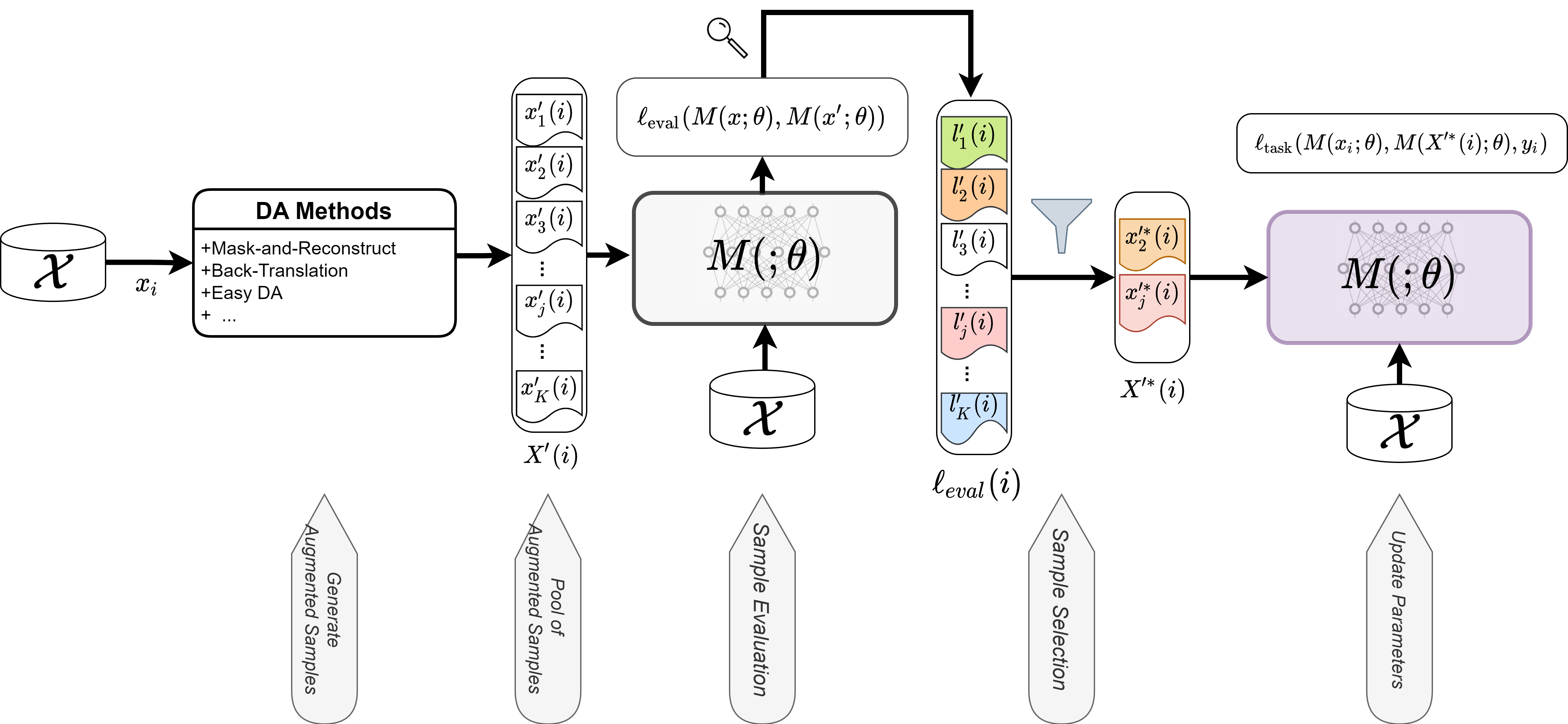 When Chosen Wisely, More Data Is What You Need: A Universal Sample-Efficient Strategy For Data AugmentationEhsan Kamalloo, Mehdi Rezagholizadeh, and Ali GhodsiIn Findings of ACL, May 2022
When Chosen Wisely, More Data Is What You Need: A Universal Sample-Efficient Strategy For Data AugmentationEhsan Kamalloo, Mehdi Rezagholizadeh, and Ali GhodsiIn Findings of ACL, May 2022Data Augmentation (DA) is known to improve the generalizability of deep neural networks. Most existing DA techniques naively add a certain number of augmented samples without considering the quality and the added computational cost of these samples. To tackle this problem, a common strategy, adopted by several state-of-the-art DA methods, is to adaptively generate or re-weight augmented samples with respect to the task objective during training. However, these adaptive DA methods: (1) are computationally expensive and not sample-efficient, and (2) are designed merely for a specific setting. In this work, we present a universal DA technique, called Glitter, to overcome both issues. Glitter can be plugged into any DA method, making training sample-efficient without sacrificing performance. From a pre-generated pool of augmented samples, Glitter adaptively selects a subset of worst-case samples with maximal loss, analogous to adversarial DA. Without altering the training strategy, the task objective can be optimized on the selected subset. Our thorough experiments on the GLUE benchmark, SQuAD, and HellaSwag in three widely used training setups including consistency training, self-distillation and knowledge distillation reveal that Glitter is substantially faster to train and achieves a competitive performance, compared to strong baselines.





2021
-
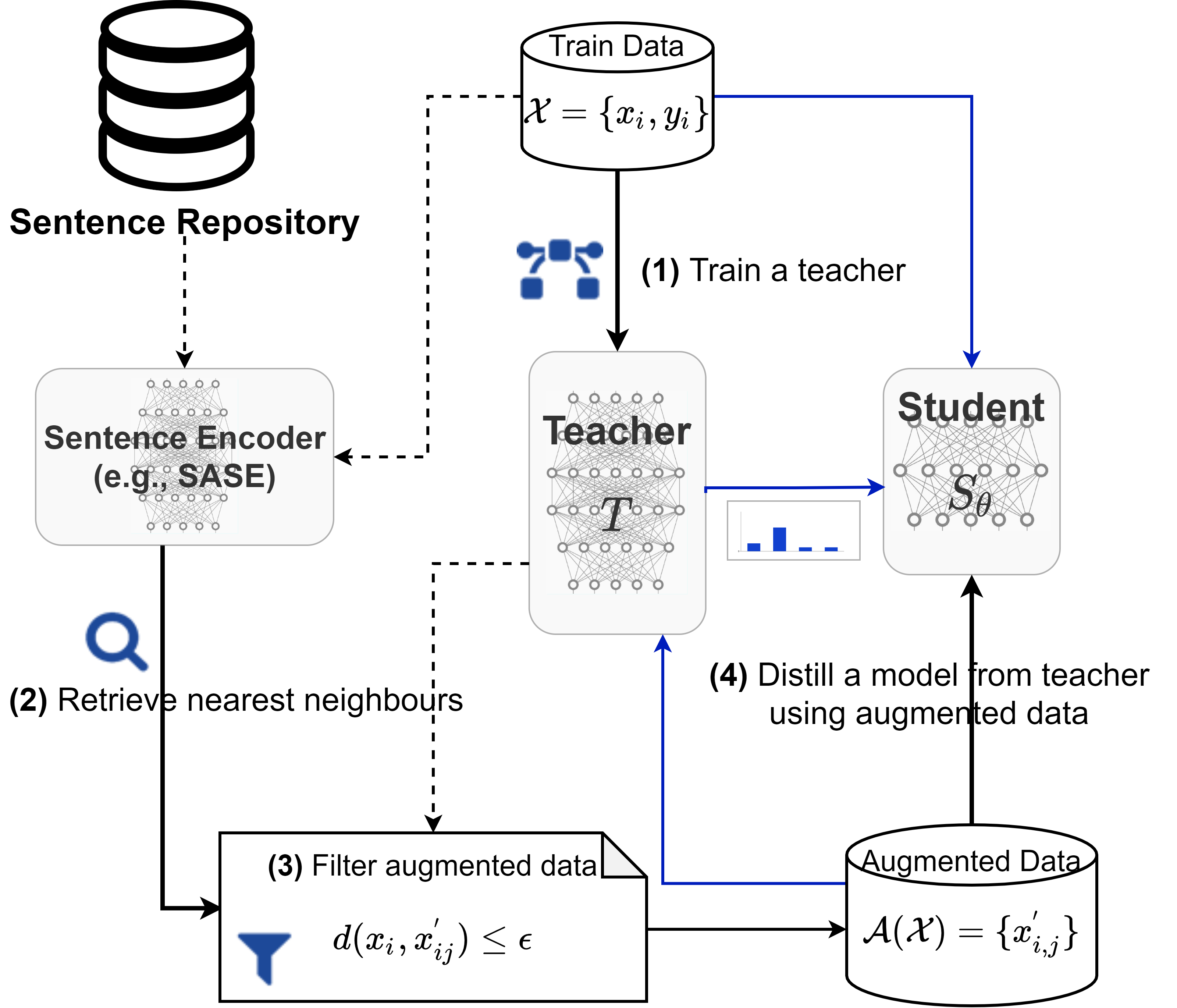 Not Far Away, Not So Close: Sample Efficient Nearest Neighbour Data Augmentation via MiniMaxEhsan Kamalloo, Mehdi Rezagholizadeh, Peyman Passban, and Ali GhodsiIn Findings of ACL, Aug 2021
Not Far Away, Not So Close: Sample Efficient Nearest Neighbour Data Augmentation via MiniMaxEhsan Kamalloo, Mehdi Rezagholizadeh, Peyman Passban, and Ali GhodsiIn Findings of ACL, Aug 2021In Natural Language Processing (NLP), finding data augmentation techniques that can produce high-quality human-interpretable examples has always been challenging. Recently, leveraging kNN such that augmented examples are retrieved from large repositories of unlabelled sentences has made a step toward interpretable augmentation. Inspired by this paradigm, we introduce Minimax-kNN, a sample efficient data augmentation strategy tailored for Knowledge Distillation (KD). We exploit a semi-supervised approach based on KD to train a model on augmented data. In contrast to existing kNN augmentation techniques that blindly incorporate all samples, our method dynamically selects a subset of augmented samples that maximizes KL-divergence between the teacher and student models. This step aims to extract the most efficient samples to ensure our augmented data covers regions in the input space with maximum loss value. We evaluated our technique on several text classification tasks and demonstrated that Minimax-kNN consistently outperforms strong baselines. Our results show that Minimax-kNN requires fewer augmented examples and less computation to achieve superior performance over the state-of-the-art kNN-based augmentation techniques.

2019
- Evaluating Coherence in Dialogue Systems using EntailmentNouha Dziri, Ehsan Kamalloo, Kory Mathewson, and Osmar ZaianeIn NAACL-HLT, Jun 2019
Evaluating open-domain dialogue systems is difficult due to the diversity of possible correct answers. Automatic metrics such as BLEU correlate weakly with human annotations, resulting in a significant bias across different models and datasets. Some researchers resort to human judgment experimentation for assessing response quality, which is expensive, time consuming, and not scalable. Moreover, judges tend to evaluate a small number of dialogues, meaning that minor differences in evaluation configuration may lead to dissimilar results. In this paper, we present interpretable metrics for evaluating topic coherence by making use of distributed sentence representations. Furthermore, we introduce calculable approximations of human judgment based on conversational coherence by adopting state-of-the-art entailment techniques. Results show that our metrics can be used as a surrogate for human judgment, making it easy to evaluate dialogue systems on large-scale datasets and allowing an unbiased estimate for the quality of the responses.
-
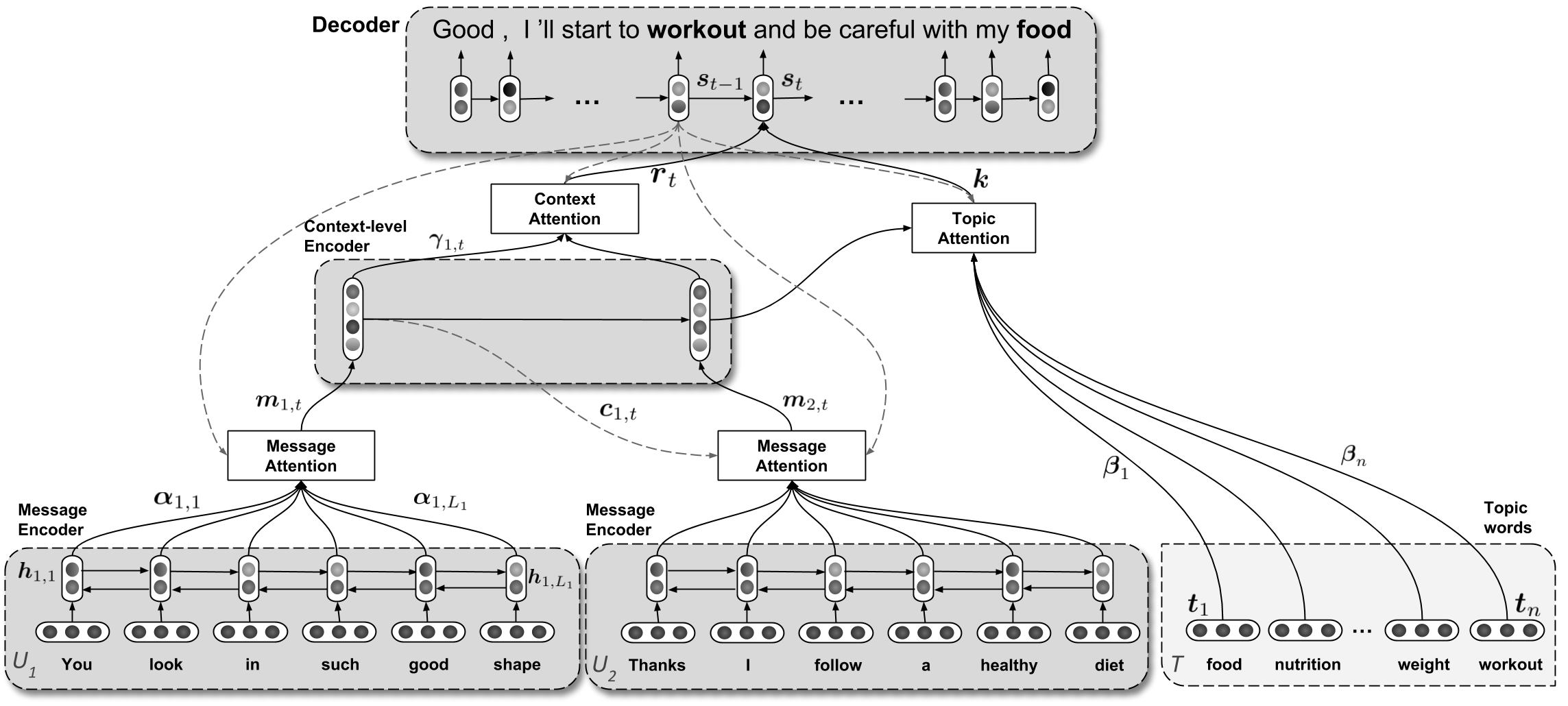 Augmenting Neural Response Generation with Context-Aware Topical AttentionNouha Dziri, Ehsan Kamalloo, Kory Mathewson, and Osmar ZaianeIn Proceedings of the First Workshop on NLP for Conversational AI (NLP4ConvAI) at ACL 2019, Aug 2019
Augmenting Neural Response Generation with Context-Aware Topical AttentionNouha Dziri, Ehsan Kamalloo, Kory Mathewson, and Osmar ZaianeIn Proceedings of the First Workshop on NLP for Conversational AI (NLP4ConvAI) at ACL 2019, Aug 2019Sequence-to-Sequence (Seq2Seq) models have witnessed a notable success in generating natural conversational exchanges. Notwithstanding the syntactically well-formed responses generated by these neural network models, they are prone to be acontextual, short and generic. In this work, we introduce a Topical Hierarchical Recurrent Encoder Decoder (THRED), a novel, fully data-driven, multi-turn response generation system intended to produce contextual and topic-aware responses. Our model is built upon the basic Seq2Seq model by augmenting it with a hierarchical joint attention mechanism that incorporates topical concepts and previous interactions into the response generation. To train our model, we provide a clean and high-quality conversational dataset mined from Reddit comments. We evaluate THRED on two novel automated metrics, dubbed Semantic Similarity and Response Echo Index, as well as with human evaluation. Our experiments demonstrate that the proposed model is able to generate more diverse and contextually relevant responses compared to the strong baselines.

2018
-
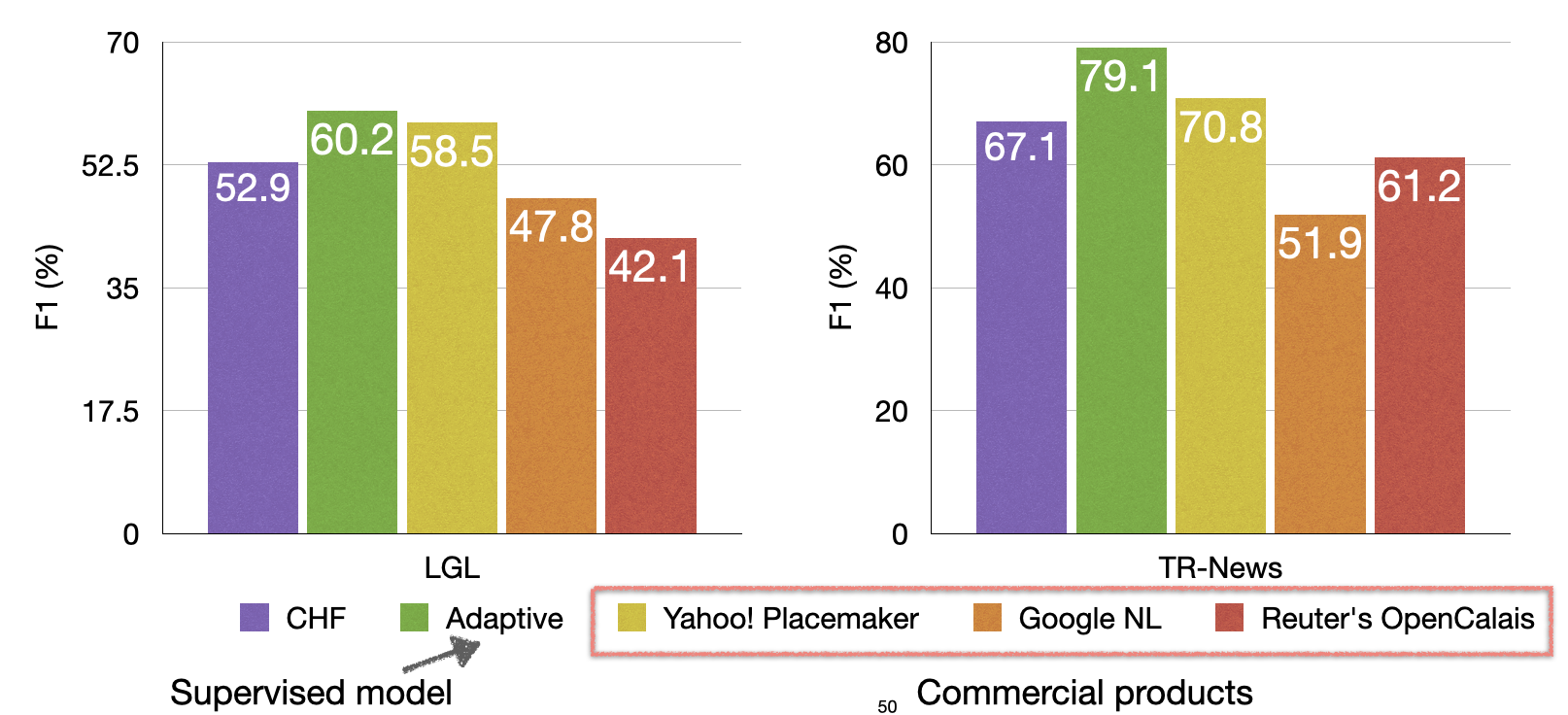 A Coherent Unsupervised Model for Toponym ResolutionEhsan Kamalloo, and Davood RafieiIn Proceedings of the 2018 World Wide Web Conference (WWW), Lyon, France, Apr 2018
A Coherent Unsupervised Model for Toponym ResolutionEhsan Kamalloo, and Davood RafieiIn Proceedings of the 2018 World Wide Web Conference (WWW), Lyon, France, Apr 2018Toponym Resolution, the task of assigning a location mention in a document to a geographic referent (i.e., latitude/longitude), plays a pivotal role in analyzing location-aware content. However, the ambiguities of natural language and a huge number of possible interpretations for toponyms constitute insurmountable hurdles for this task. In this paper, we study the problem of toponym resolution with no additional information other than a gazetteer and no training data. We demonstrate that a dearth of large enough annotated data makes supervised methods less capable of generalizing. Our proposed method estimates the geographic scope of documents and leverages the connections between nearby place names as evidence to resolve toponyms. We explore the interactions between multiple interpretations of mentions and the relationships between different toponyms in a document to build a model that finds the most coherent resolution. Our model is evaluated on three news corpora, two from the literature and one collected and annotated by us; then, we compare our methods to the state-of-the-art unsupervised and supervised techniques. We also examine three commercial products including Reuters OpenCalais, Yahoo! YQL Placemaker, and Google Cloud Natural Language API. The evaluation shows that our method outperforms the unsupervised technique as well as Reuters OpenCalais and Google Cloud Natural Language API on all three corpora; also, our method shows a performance close to that of the state-of-the art supervised method and outperforms it when the test data has 40% or more toponyms that are not seen in the training data.
